Noise Distortion Layer + Displacement parameter converted to Random =
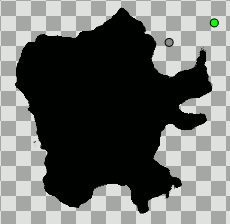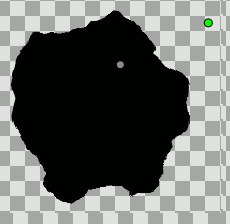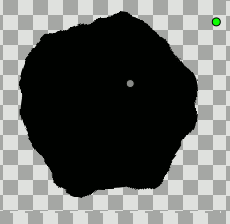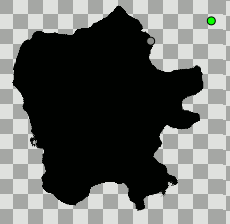
exactly what you need i think ! ?
synfig is great … synfig is big … synfig is giant … ![]() sometime too much
sometime too much ![]()
NotaBene :
just start it , at least to record and share your ideas … for my point of view i would synfig could do some kinetic things